


Let’s be sincere: now we have all been there.
It’s Friday afternoon. You’ve skilled a mannequin, validated it, and deployed the inference pipeline. The metrics look inexperienced. You shut your laptop computer for the weekend, and benefit from the break.
Monday morning, you’re greeted with the message “Pipeline failed” when checking into work. What’s occurring? Every part was excellent whenever you deployed the inference pipeline.
The reality is that the problem might be a variety of issues. Possibly the upstream engineering group modified the user_id column from an integer to a string. Or possibly the worth column all of a sudden comprises damaging numbers. Or my private favourite: the column title modified from created_at to createdAt (camelCase strikes once more!).
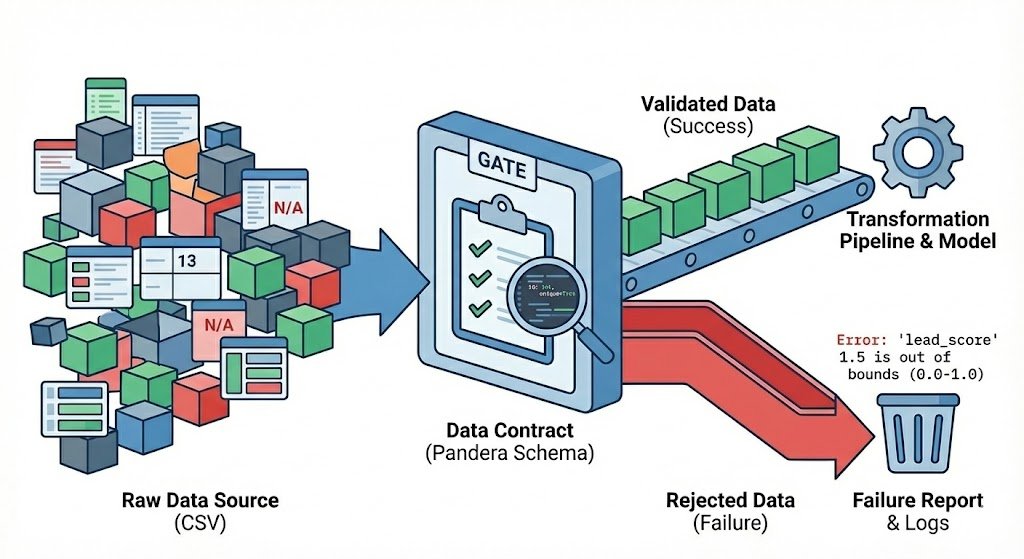
The business calls this Schema Drift. I name it a headache.
Currently, individuals are speaking lots about Information Contracts. Normally, this includes promoting you an costly SaaS platform or a posh microservices structure. However if you’re only a Information Scientist or Engineer attempting to maintain your Python pipelines from exploding, you don’t essentially want enterprise bloat.
The Device: Pandera
Let’s undergo methods to create a easy knowledge contract in Python utilizing the library Pandera. It’s an open-source Python library that lets you outline schemas as class objects. It feels similar to Pydantic (in case you’ve used FastAPI), however it’s constructed particularly for DataFrames.
To get began, you may merely set up pandera utilizing pip:
pip set up panderaA Actual-Life Instance: The Advertising Leads Feed
Let’s take a look at a basic situation. You’re ingesting a CSV file of promoting leads from a third-party vendor.
Here’s what we count on the information to appear like:
- id: An integer (have to be distinctive).
- electronic mail: A string (should really appear like an electronic mail).
- signup_date: A sound datetime object.
- lead_score: A float between 0.0 and 1.0.
Right here is the messy actuality of our uncooked knowledge that we recieve:
import pandas as pd
import numpy as np
# Simulating incoming knowledge that MIGHT break our pipeline
knowledge = {
"id": [101, 102, 103, 104],
"electronic mail": ["[email protected]", "[email protected]", "INVALID_EMAIL", "[email protected]"],
"signup_date": ["2024-01-01", "2024-01-02", "2024-01-03", "2024-01-04"],
"lead_score": [0.5, 0.8, 1.5, -0.1] # Be aware: 1.5 and -0.1 are out of bounds!
}
df = pd.DataFrame(knowledge)Should you fed this dataframe right into a mannequin anticipating a rating between 0 and 1, your predictions could be rubbish. Should you tried to hitch on id and there have been duplicates, your row counts would explode. Messy knowledge results in messy knowledge science!
Step 1: Outline The Contract
As a substitute of writing a dozen if statements to examine knowledge high quality, we outline a SchemaModel. That is our contract.
import pandera as pa
from pandera.typing import Collection
class LeadsContract(pa.SchemaModel):
# 1. Verify knowledge sorts and existence
id: Collection[int] = pa.Discipline(distinctive=True, ge=0)
# 2. Verify formatting utilizing regex
electronic mail: Collection[str] = pa.Discipline(str_matches=r"[^@]+@[^@]+.[^@]+")
# 3. Coerce sorts (convert string dates to datetime objects mechanically)
signup_date: Collection[pd.Timestamp] = pa.Discipline(coerce=True)
# 4. Verify enterprise logic (bounds)
lead_score: Collection[float] = pa.Discipline(ge=0.0, le=1.0)
class Config:
# This ensures strictness: if an additional column seems, or one is lacking, throw an error.
strict = TrueLook over the code above to get the overall really feel for a way Pandera units up a contract. You may fear concerning the particulars later whenever you look via the Pandera documentation.
Step 2: Implement The Contract
Now, we have to apply the contract we made to our knowledge. The naive manner to do that is to run LeadsContract.validate(df). This works, nevertheless it crashes on the first error it finds. In manufacturing, you normally need to know every part that’s flawed with the file, not simply the primary row.
We are able to allow “lazy” validation to catch all errors directly.
strive:
# lazy=True means "discover all errors earlier than crashing"
validated_df = LeadsContract.validate(df, lazy=True)
print("Information handed validation! Continuing to ETL...")
besides pa.errors.SchemaErrors as err:
print("⚠️ Information Contract Breached!")
print(f"Whole errors discovered: {len(err.failure_cases)}")
# Let us take a look at the precise failures
print("nFailure Report:")
print(err.failure_cases[['column', 'check', 'failure_case']])The Output
Should you run the code above, you gained’t get a generic KeyError. You’re going to get a particular report detailing precisely why the contract was breached:
⚠️ Information Contract Breached!
Whole errors discovered: 3
Failure Report:
column examine failure_case
0 electronic mail str_matches INVALID_EMAIL
1 lead_score less_than_or_equal_to 1.5
2 lead_score greater_than_or_equal_to -0.1In a extra life like situation, you’d most likely log the output to a file and arrange alerts so that you simply get notified with one thing is damaged.
Why This Issues
This method shifts the dynamic of your work.
With out a contract, your code fails deep contained in the transformation logic (or worse, it doesn’t fail, and also you write unhealthy knowledge to the warehouse). You spend hours debugging NaN values.
With a contract:
- Fail Quick: The pipeline stops on the door. Dangerous knowledge by no means enters your core logic.
- Clear Blame: You may ship that Failure Report again to the information supplier and say, “Rows 3 and 4 violated the schema. Please repair.”
- Documentation: The
LeadsContractclass serves as residing documentation. New joiners to the venture don’t have to guess what the columns characterize; they will simply learn the code. You additionally keep away from establishing a separate knowledge contract in SharePoint, Confluence, or wherever that rapidly get outdated.
The “Good Sufficient” Resolution
You may undoubtedly go deeper. You may combine this with Airflow, push metrics to a dashboard, or use instruments like great_expectations for extra complicated statistical profiling.
However for 90% of the use instances I see, a easy validation step firstly of your Python script is sufficient to sleep soundly on a Friday evening.
Begin small. Outline a schema on your messiest dataset, wrap it in a strive/catch block, and see what number of complications it saves you this week. When this straightforward method is just not appropriate anymore, THEN I’d take into account extra elaborate instruments for knowledge contacts.
If you’re taken with AI, knowledge science, or knowledge engineering, please comply with me or join on LinkedIn.














{kind=link}