


For SaaS (software program as a service) corporations, monitoring and managing their product information is essential. For many who fail to know this, by the point they discover an incident. Injury is already performed. For struggling corporations, this may be deadly.
To stop this, I constructed an n8n workflow linked to their database that may analyze the info each day, spot if there may be any incident. On this case, a log and notification system will begin to examine as quickly as doable. I additionally constructed a dashboard so the workforce might see the ends in actual time.

Context
A B2B SaaS platform specializing in information visualization and automatic reporting serves roughly 4500 prospects, dispersed in three segments:
- Small enterprise
- Mid-market
- Enterprise
The weekly product utilization exceeds 30000 lively accounts with sturdy dependencies on real-time information (pipelines, APIs, dashboards, background jobs).
The product workforce works carefully with:
- Progress (acquisition, activation, onboarding)
- Income (pricing, ARPU, churn)
- SRE/Infrastructure (reliability, availability)
- Information Engineering (pipelines, information freshness)
- Assist and buyer success

Final 12 months, the corporate noticed a rising variety of incidents. Between October and December, the entire of incidents elevated from 250 to 450, an 80% enhance. With this enhance, there have been greater than 45 Excessive and important incidents that affected 1000’s of customers. Essentially the most affected metrics have been:
- api_error_rate
- checkout_success_rate
- net_mrr_delta
- data_freshness_lag_minutes
- churn_rate

When incidents happen, a firm is judged by its prospects based mostly on the way it handles and reacts. Whereas the product workforce is esteemed for a way they managed it and ensured it received’t occur once more.
Having an incident as soon as can occur, however having the identical incident twice is a fault.
Enterprise impression
- Extra volatility in internet recurring income
- A noticeable decline in lively accounts over a number of consecutive weeks
- A number of enterprise prospects reporting and complaining in regards to the outdated dashboard (as much as 45+minutes late)

In whole, between 30000 and 60000 customers have been impacted. Buyer confidence in product reliability additionally suffered. Amongst non-renewals, 45% identified that’s their most important motive.
Why is that this problem crucial?
As an information platform, the corporate can not afford to have:
- sluggish or stale information
- Api error
- Pipeline failures
- Missed or delayed synchronizations
- Inaccurate dashboard
- Churns (downgrades, cancellations)

Internally, the incidents have been unfold throughout a number of programs:
- Notions for product monitoring
- Slack for alerts
- PostgreSQL for storage
- Even on Google Sheets for buyer assist

There was not a single supply of reality. The product workforce has to manually cross-reference and double-check all information, looking for traits and piecing collectively. It was an investigation and resolving a puzzle, making them lose so many hours weekly.
Answer: Automating an incident system alert with N8N and constructing an information dashboard. So, incidents are detected, tracked, resolved and understood.
Why n8n?
At present, there are a number of automation platforms and options. However not all are matching the wants and necessities. Deciding on the appropriate one following the necessity is important.
The precise necessities have been to have entry to a database with out an API wanted (n8n helps Api), to have visible workflows and nodes for a non-technical individual to know, custom-coded nodes, self-hosted choices and cost-effective at scale. So, amongst the platforms current like Zapier, Make or n8n, the selection was for the final.
Designing the Product Well being Rating

First, the important thing metrics should be decided and calculated.
Impression rating: easy operate of severity + delta + scale of customers
impact_score = (
severity_weights[severity] * 10
+ abs(delta_pct) * 0.8
+ np.log1p(affected_users)
)
impact_score = spherical(float(impact_score), 2)Precedence: derived from severity + impression
if severity == "crucial" or impact_score > 60:
precedence = "P1"
elif severity == "excessive" or impact_score > 40:
precedence = "P2"
elif severity == "medium":
precedence = "P3"
else:
precedence = "P4"Product well being rating
def compute_product_health_score(incidents, metrics):
"""
Rating = 100 - sum(penalties)
Manufacturing model handles 15+ components
"""
# Key perception: penalties have completely different max weights
penalties = {
'quantity': min(40, incident_rate * 13), # 40% max
'severity': calculate_severity_sum(incidents), # 25% max
'customers': min(15, log(customers) / log(50000) * 15), # 15% max
'traits': calculate_business_trends(metrics) # 20% max
}
rating = 100 - sum(penalties.values())
if rating >= 80: return rating, "🟢 Steady"
elif rating >= 60: return rating, "🟡 Underneath watch"
else: return rating, "🔴 In danger"Designing the Automated Detection System with n8n

This technique consists of 4 streams:
- Stream 1: retrieves current income metrics, identifies uncommon spikes in churn MRR, and creates incidents when wanted.

const rows = objects.map(merchandise => merchandise.json);
if (rows.size < 8) {
return [];
}
rows.type((a, b) => new Date(a.date) - new Date(b.date));
const values = rows.map(r => parseFloat(r.churn_mrr || 0));
const lastIndex = rows.size - 1;
const lastRow = rows[lastIndex];
const lastValue = values[lastIndex];
const window = 7;
const baselineValues = values.slice(lastIndex - window, lastIndex);
const imply = baselineValues.scale back((s, v) => s + v, 0) / baselineValues.size;
const variance = baselineValues
.map(v => Math.pow(v - imply, 2))
.scale back((s, v) => s + v, 0) / baselineValues.size;
const std = Math.sqrt(variance);
if (std === 0) {
return [];
}
const z = (lastValue - imply) / std;
const deltaPct = imply === 0 ? null : ((lastValue - imply) / imply) * 100;
if (z > 2) {
const anomaly = {
date: lastRow.date,
metric_name: 'churn_mrr',
baseline_value: imply,
actual_value: lastValue,
z_score: z,
delta_pct: deltaPct,
severity:
deltaPct !== null && deltaPct > 50 ? 'excessive'
: deltaPct !== null && deltaPct > 25 ? 'medium'
: 'low',
};
return [{ json: anomaly }];
}
return [];- Stream 2: Screens function utilization metrics to detect sudden drops in adoption or engagement.
Incidents are logged with severity, context, and alerts to the product workforce.

- Stream 3: For each open incident, collects further context from the database (e.g., churn by nation or plan), makes use of AI to generate a transparent root trigger speculation and prompt subsequent steps, sends a summarized report back to Slack and e-mail and updates the incident

- Stream 4: Each morning, the workflow compiles all incidents from the day before today, creates a Notion web page for documentation and sends a report back to the management workforce

We deployed comparable detection nodes for 8 completely different metrics, adjusting the z-score course based mostly on whether or not will increase or decreases have been problematic.
The AI agent receives further context by means of SQL queries (churn by nation, by plan, by section) to generate extra correct root trigger hypotheses. And all of this information is gathered and despatched in a each day e-mail.
The workflow generates each day abstract reviews aggregating all incidents by metric and severity, distributed through e-mail and Slack to stakeholders.
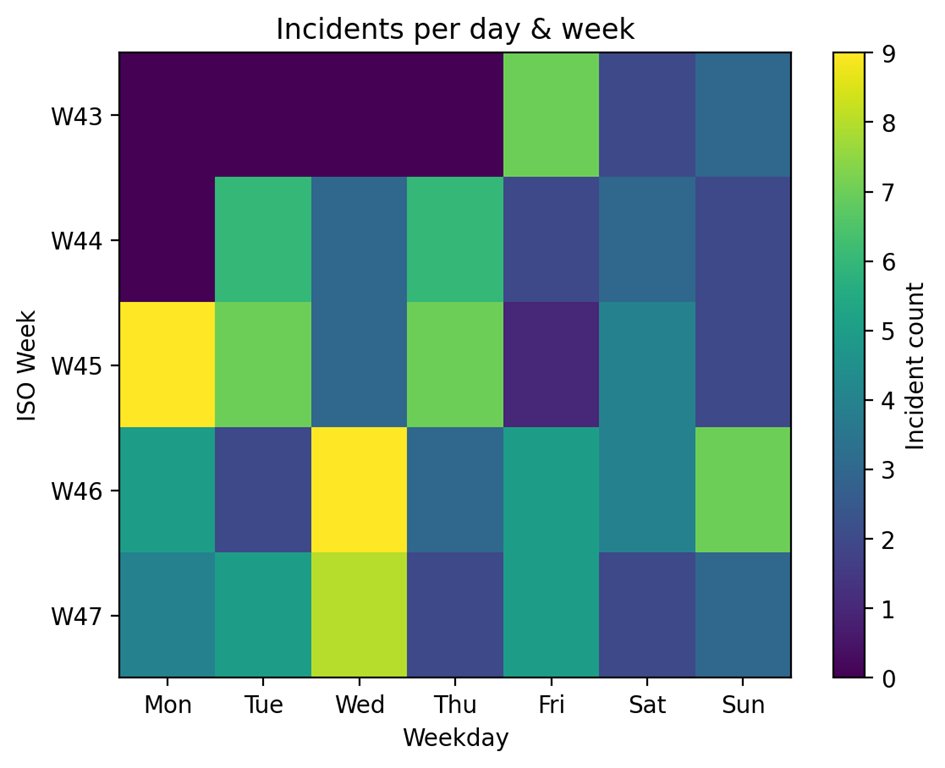
The dashboard
The dashboard is consolidating all indicators into one place. An computerized product well being rating with a 0-100 base is calculated with:
- incident quantity
- severity weighting
- open vs resolved standing
- variety of customers impacted
- enterprise traits (MRR)
- utilization traits (lively accounts)
A section breakdown to determine which buyer teams are probably the most affected:

A weekly heatmap and time collection pattern charts to determine recurring patterns:

And an in depth incident view composed by:
- Enterprise context
- Dimension & section
- Root trigger speculation
- Incident kind
- An AI abstract to speed up communication and diagnoses coming from the n8n workflow

Analysis:
The product well being rating famous the precise product 24/100 with the standing “in danger” with:
- 45 Excessive & Important incidents
- 36 incidents over the past 7 days
- 33,385 estimated affected usersNegative pattern in churn and DAU
- A number of spikes in api_error_rate and drops in checkout_success_rate

Largest impression per segments:
- Enterprise → crucial information freshness points
- Mid-Market → recurring incidents on function adoption
- SMB → fluctuations in onboarding & activation

Impression
The purpose of this dashboard shouldn’t be solely to investigate incidents and determine patterns however to allow the group to react quicker with an in depth overview.

We seen a 35% discount in crucial incidents after 2 months. SRE & DATA groups recognized the recurring root reason for some main points, because of the unified information, and have been capable of repair it and monitor the upkeep. Incident response time improved dramatically because of the AI summaries and all of the metrics, permitting them to know the place to research.
An AI-Powered Root Trigger Evaluation

Utilizing AI can save loads of time. Particularly when an investigation is required in several databases, and also you don’t know the place to start out. Including an AI agent within the loop can prevent a substantial period of time because of its pace of processing information. To acquire this, a detailed immediate is critical as a result of the agent will change a human. So, to have probably the most correct outcomes, even the AI wants to know the context and obtain some steerage. In any other case, it might examine and draw irrelevant conclusions. Don’t overlook to ensure you have a full understanding of the reason for the problem.
You're a Product Information & Income Analyst.
We detected an incident:
{{ $json.incident }}
Right here is churn MRR by nation (high offenders first):
{{ $json.churn_by_country }}
Right here is churn MRR by plan:
{{ $json.churn_by_plan }}
1. Summarize what occurred in easy enterprise language.
2. Determine probably the most impacted segments (nation, plan).
3. Suggest 3-5 believable hypotheses (product points, worth modifications, bugs, market occasions).
4. Suggest 3 concrete subsequent steps for the Product workforce.It’s important to notice that when the outcomes are obtained, a closing test is critical to make sure the evaluation was appropriately performed. AI is a software, however it will probably additionally go unsuitable, so don’t solely on it; it’s a useful software. For this technique, the AI will counsel the high 3 probably root causes for every incident.

A greater alignment with the management workforce and reporting based mostly on the info. The whole lot grew to become extra data-driven with deeper analyses, not instinct or reviews by segmentation. This additionally led to an improved course of.
Conclusion & takeaways
In conclusion, constructing a product well being dashboard has a number of advantages:
- Detect damaging traits (MRR, DAU, engagement) earlier
- Scale back crucial incidents by figuring out root-cause patterns
- Perceive actual enterprise impression (customers affected, churn threat)
- Prioritize the product roadmap based mostly on threat and impression
- Align Product, Information, SRE, and Income round a single supply of reality
That’s precisely what many corporations lack: a unified information method.

Utilizing the n8n workflow helped in two methods: with the ability to resolve the problems as quickly as doable and collect the info in a single place. The automation software helped scale back the time spent on this process because the enterprise was nonetheless working.
Classes for Product groups

- Begin easy: constructing an automation system and a dashboard must be clearly outlined. You aren’t constructing a product for the shoppers, you might be constructing a product in your collaborators. It’s important that you just perceive every workforce’s wants since they’re your core customers. With that in thoughts, have the product that shall be your MVP and reply to all of your wants first. Then you possibly can enhance it by including options or metrics.
- Unified metrics matter extra than good detection: now we have to understand that will probably be because of them that the time shall be saved, together with understanding. Having good detection is important, but when the metrics are inaccurate, the time saved shall be wasted by the groups searching for the metrics scattered throughout completely different environments
- Automation saves 10 hours per week of handbook investigation: by automating some handbook and recurring duties, you’ll save hours investigating, as with the incident alert workflow, we all know instantly the place to research first and the speculation of the trigger and even some motion to take.
- Doc every little thing: a correct and detailed documentation is a should and can permit all of the events concerned to have a transparent understanding and views about what is going on. Documentation can be a bit of knowledge.
Who am I ?
I’m Yassin, a Venture Supervisor who expanded into Information Science to bridge the hole between enterprise selections and technical programs. Studying Python, SQL, and analytics has enabled me to design product insights and automation workflows that join what groups want with how information behaves. Let’s join on Linkedin















{kind=link}