



of AI hype, it seems like everyone seems to be utilizing Imaginative and prescient-Language Fashions and enormous Imaginative and prescient Transformers for each downside in Pc Imaginative and prescient. Many individuals see these instruments as one-size-fits-all options and instantly use the newest, shiniest mannequin as a substitute of understanding the underlying sign they need to extract. However oftentimes there’s magnificence to simplicity. It’s one of the vital necessary classes I’ve discovered as an engineer: don’t overcomplicate options to easy issues.

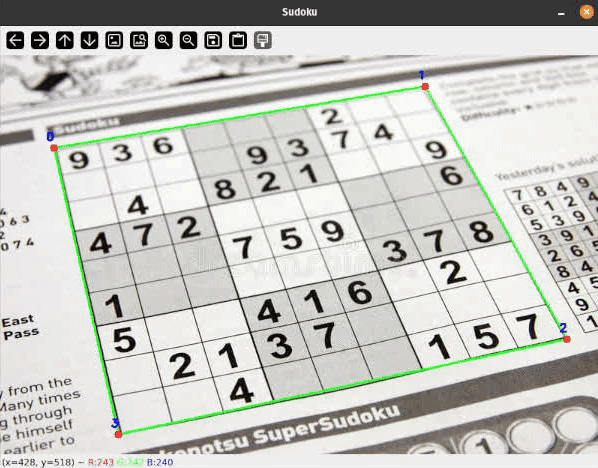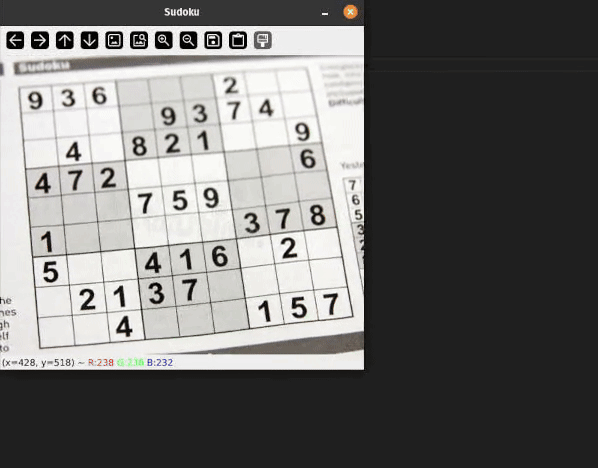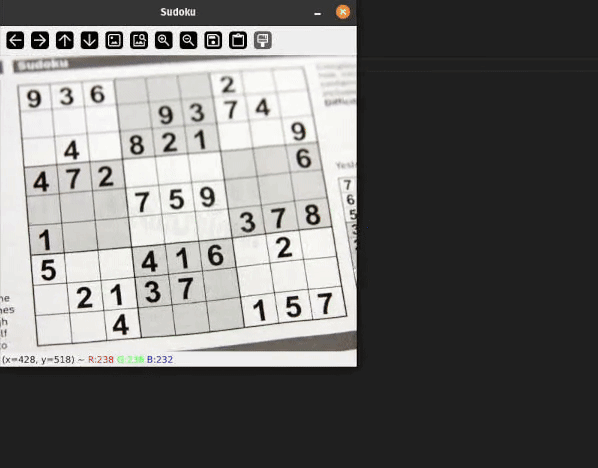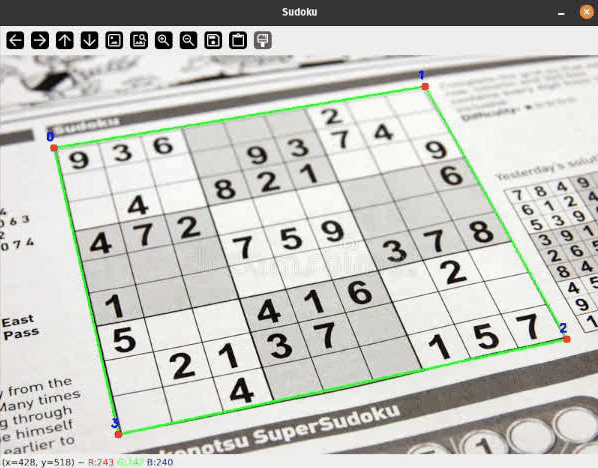
Let me present you a sensible software of some easy classical Pc Imaginative and prescient strategies to detect rectangular objects on flat surfaces and apply a perspective transformation to rework the skewed rectangle. Related strategies are broadly used, for instance, in doc scanning and extraction purposes.
Alongside the way in which you’ll study some attention-grabbing ideas from normal classical Pc Imaginative and prescient strategies to how you can order polygon factors and why that is associated to a combinatoric project downside.
Overview
- Detection
- Grayscale
- Edge Detection
- Dilation
- Contour Detection
- Perspective Transformation
- Variant A: Easy kind primarily based on sum/diff
- Variant B: Task Optimization Downside
- Variant C: Cyclic sorting with anchor
- Making use of the Perspective Transformation
- Conclusion
Detection
To detect Sudoku grids I thought-about many various approaches starting from easy thresholding, hough line transformations or some type of edge detection to coaching a deep studying mannequin for segmentation or keypoint detection.
Let’s outline some assumptions to scope the issue:
- The Sudoku grid is clearly and absolutely seen within the body with a transparent quadrilateral border, with sturdy distinction from the background.
- The floor on which the Sudoku grid is printed must be flat, however will be captured from an angle and seem skewed or rotated.

I’ll present you a easy pipeline with some filtering steps to detect the bounds of our Sudoku grid. On a excessive degree, the processing pipeline seems to be as follows:


Grayscale
On this first step we merely convert the enter picture from its three coloration channels to a single channel grayscale picture, as we don’t want any coloration info to course of these pictures.
def find_sudoku_grid(
picture: np.ndarray,
) -> np.ndarray | None:
"""
Finds the most important square-like contour in a picture, doubtless the Sudoku grid.
Returns:
The contour of the discovered grid as a numpy array, or None if not discovered.
"""
grey = cv2.cvtColor(picture, cv2.COLOR_BGR2GRAY)Edge Detection
After changing the picture to grayscale we will use the Canny edge detection algorithm to extract edges. There are two thresholds to decide on for this algorithm that decide if pixels are accepted as edges:

In our case of detecting Sudoku grids, we assume very sturdy edges on the border traces of our grid. We will select a excessive higher threshold to reject noise from showing in our masks, and a decrease threshold not too low to reject small noisy edges linked to the principle border from displaying up in our masks.
A blur filter is usually used earlier than passing pictures to Canny to scale back noise, however on this case the perimeters are very sturdy however slender, therefore the blur is omitted.
def find_sudoku_grid(
picture: np.ndarray,
canny_threshold_1: int = 100,
canny_threshold_2: int = 255,
) -> np.ndarray | None:
"""
Finds the most important square-like contour in a picture, doubtless the Sudoku grid.
Args:
picture: The enter picture.
canny_threshold_1: Decrease threshold for the Canny edge detector.
canny_threshold_2: Higher threshold for the Canny edge detector.
Returns:
The contour of the discovered grid as a numpy array, or None if not discovered.
"""
...
canny = cv2.Canny(grey, threshold1=canny_threshold_1, threshold2=canny_threshold_2)
Dilation
On this subsequent step, we post-process the sting detection masks with a dilation kernel to shut small gaps within the masks.
def find_sudoku_grid(
picture: np.ndarray,
canny_threshold_1: int = 100,
canny_threshold_2: int = 255,
morph_kernel_size: int = 3,
) -> np.ndarray | None:
"""
Finds the most important square-like contour in a picture, doubtless the Sudoku grid.
Args:
picture: The enter picture.
canny_threshold_1: First threshold for the Canny edge detector.
canny_threshold_2: Second threshold for the Canny edge detector.
morph_kernel_size: Measurement of the morphological operation kernel.
Returns:
The contour of the discovered grid as a numpy array, or None if not discovered.
"""
...
kernel = cv2.getStructuringElement(
form=cv2.MORPH_RECT, ksize=(morph_kernel_size, morph_kernel_size)
)
masks = cv2.morphologyEx(canny, op=cv2.MORPH_DILATE, kernel=kernel, iterations=1)
Contour Detection
Now that the binary masks is prepared, we will run a contour detection algorithm to search out coherent blobs and filter all the way down to a single contour with 4 factors.
contours, _ = cv2.findContours(
masks, mode=cv2.RETR_EXTERNAL, methodology=cv2.CHAIN_APPROX_SIMPLE
)
This preliminary contour detection will return a listing of contours that comprise each single pixel that’s a part of the contour. We will use the Douglas–Peucker algorithm to iteratively cut back the variety of factors within the contour and approximate the contour with a easy polygon. We will select a minimal distance between factors for the algorithm.


If we assume that even for a few of the most skewed rectangle, the shortest aspect is not less than 10% of the circumference of the form, we will filter the contours all the way down to polygons with precisely 4 factors.
contour_candidates: record[np.ndarray] = []
for cnt in contours:
# Approximate the contour to a polygon
epsilon = 0.1 * cv2.arcLength(curve=cnt, closed=True)
approx = cv2.approxPolyDP(curve=cnt, epsilon=epsilon, closed=True)
# Preserve solely polygons with 4 vertices
if len(approx) == 4:
contour_candidates.append(approx)Lastly we take the most important detected contour, presumably the ultimate Sudoku grid. We kind the contours by space in reverse order after which take the primary component, equivalent to the most important contour space.
best_contour = sorted(contour_candidates, key=cv2.contourArea, reverse=True)[0]
Perspective Transformation
Lastly we have to rework the detected grid again to its sq.. To attain this, we will use a perspective transformation. The transformation matrix will be calculated by specifying the place the 4 factors of our Sudoku grid contour must be positioned ultimately: the 4 corners of the picture.
rect_dst = np.array(
[[0, 0], [width - 1, 0], [width - 1, height - 1], [0, height - 1]],
)
To match the contour factors to the corners, they must be ordered first, to allow them to be assigned accurately. Let’s outline the next order for our nook factors:

Variant A: Easy kind primarily based on sum/diff
To kind the extracted corners and assign them to those goal factors, a easy algorithm might take a look at the sum and variations of the x and y coordinates for every nook.
p_sum = p_x + p_y
p_diff = p_x - p_yBased mostly on these values, it’s now potential to distinguish the corners:
- The highest left nook has each a small x and y worth, it has the smallest sum
argmin(p_sum) - Backside proper nook has the most important sum
argmax(p_sum) - High proper nook has the most important diff
argmax(p_diff) - Backside left nook has the smallest distinction
argmin(p_diff)
Within the following animation, I attempted to visualise this project of the 4 corners of a rotating sq.. The coloured traces symbolize the respective picture nook assigned to every sq. nook.

def order_points(pts: np.ndarray) -> np.ndarray:
"""
Orders the 4 nook factors of a contour in a constant
top-left, top-right, bottom-right, bottom-left sequence.
Args:
pts: A numpy array of form (4, 2) representing the 4 corners.
Returns:
A numpy array of form (4, 2) with the factors ordered.
"""
# Reshape from (4, 1, 2) to (4, 2) if wanted
pts = pts.reshape(4, 2)
rect = np.zeros((4, 2), dtype=np.float32)
# The highest-left level can have the smallest sum, whereas
# the bottom-right level can have the most important sum
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# The highest-right level can have the smallest distinction,
# whereas the bottom-left can have the most important distinction
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rectThis works properly except the rectangle is closely skewed, like the next one. On this case, you may clearly see that this methodology is flawed, as there the identical rectangle nook is assigned a number of picture corners.

Variant B: Task Optimization Downside
One other method can be to reduce the distances between every level and its assigned nook. This may be carried out utilizing a pairwise_distances calculation between every level and the corners and the linear_sum_assignment perform from scipy, which solves the project downside whereas minimizing a price perform.
def order_points_simplified(pts: np.ndarray) -> np.ndarray:
"""
Orders a set of factors to greatest match a goal set of nook factors.
Args:
pts: A numpy array of form (N, 2) representing the factors to order.
Returns:
A numpy array of form (N, 2) with the factors ordered.
"""
# Reshape from (N, 1, 2) to (N, 2) if wanted
pts = pts.reshape(-1, 2)
# Calculate the gap between every level and every goal nook
D = pairwise_distances(pts, pts_corner)
# Discover the optimum one-to-one project
# row_ind[i] ought to be matched with col_ind[i]
row_ind, col_ind = linear_sum_assignment(D)
# Create an empty array to carry the sorted factors
ordered_pts = np.zeros_like(pts)
# Place every level within the right slot primarily based on the nook it was matched to.
# For instance, the purpose matched to target_corners[0] goes into ordered_pts[0].
ordered_pts[col_ind] = pts[row_ind]
return ordered_pts
Though this resolution works, it isn’t supreme, because it depends on the picture distance between the form factors and the corners and it’s computationally costlier as a result of a distance matrix needs to be constructed. After all right here within the case of 4 factors assigned that is negligible, however this resolution wouldn’t be properly fitted to a polygon with many factors!
Variant C: Cyclic sorting with anchor
This third variant is a really light-weight and environment friendly strategy to kind and assign the factors of the form to the picture corners. The thought is to calculate an angle for every level of the form primarily based on the centroid place.

For the reason that angles are cyclic, we have to select an anchor to ensure absolutely the order of the factors. We merely choose the purpose with the bottom sum of x and y.
def order_points(self, pts: np.ndarray) -> np.ndarray:
"""
Orders factors by angle across the centroid, then rotates to begin from top-left.
Args:
pts: A numpy array of form (4, 2).
Returns:
A numpy array of form (4, 2) with factors ordered."""
pts = pts.reshape(4, 2)
heart = pts.imply(axis=0)
angles = np.arctan2(pts[:, 1] - heart[1], pts[:, 0] - heart[0])
pts_cyclic = pts[np.argsort(angles)]
sum_of_coords = pts_cyclic.sum(axis=1)
top_left_idx = np.argmin(sum_of_coords)
return np.roll(pts_cyclic, -top_left_idx, axis=0)
We will now use this perform to kind our contour factors:
rect_src = order_points(grid_contour)Making use of the Perspective Transformation
Now that we all know which factors must go the place, we will lastly transfer on to probably the most attention-grabbing half: creating and really making use of the attitude transformation to the picture.

Since we have already got our record of factors for the detected quadrilateral sorted in rect_src, and we’ve got our goal nook factors in rect_dst, we will use the OpenCV methodology for calculating the transformation matrix:
warp_mat = cv2.getPerspectiveTransform(rect_src, rect_dst)The result’s a 3×3 warp matrix, defining how you can rework from a skewed 3D perspective view to a 2D flat top-down view. To get this flat top-down view of our Sudoku grid, we will apply this angle transformation to our authentic picture:
warped = cv2.warpPerspective(img, warp_mat, (side_len, side_len))And voilà, we’ve got our completely sq. Sudoku grid!

Conclusion
On this challenge we walked via a easy pipeline utilizing classical Pc Imaginative and prescient strategies to extract Sudoku grids from photos. These strategies present a easy strategy to detect the bounds of the Sudoku grids. After all resulting from its simplicity there are some limitations to how properly this method generalizes to totally different settings and excessive environments akin to low mild or exhausting shadows. Utilizing a deep-learning primarily based method might make sense if the detection must generalize to an enormous quantity of various settings.
Subsequent, a perspective transformation is used to get a flat top-down view of the grid. This picture can now be utilized in additional processing, akin to extracting the numbers within the grid and really fixing the Sudoku. In a subsequent article we’ll look additional into these pure subsequent steps on this challenge.
Take a look at the supply code of the challenge under and let me know you probably have any questions or ideas on this challenge. Till then, completely happy coding!
For extra particulars and the total implementation together with the code for the all of the animations and visualizations, take a look at the supply code of this challenge on my GitHub:
https://github.com/trflorian/sudoku-extraction
All visualizations on this publish had been created by the creator.
















{kind=link}